2023 IEEE International Conference on Big Data (BigData)
Supporting Practical URI Mappings in Virtual Knowledge Graph-based Relational Data Integration
-
Shogo Sato Programs in Engineering Sciences University of Tsukuba Tsukuba, Japan
-
Tadashi Masuda Center of Computational Sciences University of Tsukuba Tsukuba, Japan
-
Toshiyuki Amagasa Center of Computational Sciences University of Tsukuba Tsukuba, Japan
Abstract
In this paper, we address the problem of mapping identifiers in non-RDF data to URIs. Virtual knowledge graphs (VKGs), where non-RDF data, such as relational databases, CSV files, etc., are published as RDF data, allowing users to access them using a standard query language (SPARQL), has been gaining much attention to integrating heterogeneous data. There have been several VKG systems, but there has been a problem of assigning an appropriate URI to an entity included in a record, and existing systems only support simple methods to generate a URI by adding a URI prefix to the ID value in a record. However, in practice, more complex mappings are needed to meet the demands of real applications. To address this problem, we proposed to extend the relation-to-RDF mapping rules where users are allowed to specify how entities in relations are mapped to URIs in terms of a user-defined URI function. More precisely, we integrate this method into our relation-to-RDF mapping framework. We conduct a set of experiments to assess the feasibility of the proposed method.
- Index Terms—query rewriting, RDF, SPARQL, data integration
I. INTRODUCTION
In recent years, open data become widely available and has been used for wide spectrum of applications (e.g., Open Data 100 [1]). For example, DATA.GO.JP [2], the open data released by the Japanese government, provides us with various government-related data, such as weather and population, in computer-readable forms. When utilizing such data, it is essential to integrate data from multiple sources, including open data and conventional data stored in databases [3].
In the meantime, RDF (Resource Description Framework) [4] and SPARQL (SPARQL Protocol and RDF Query Language) [5] have attracted attention as a standardized way to represent and query open data. The basic RDF data model is the edge-labeled graph comprising a set of triples consisting of subject, predicate, and object. SPARQL allows users to query RDF data by subgraph matching based on basic graph patterns (BGPs). Thanks to the flexibility and expressiveness of RDF, various kinds of data can be mapped to an RDF graph. For this reason, RDF has been recognized as the most popular way to represent knowledge graphs (KGs) and a common data model for heterogeneous data integration.
Virtual knowledge graphs (VkGs) [6] is a framework for integrating heterogeneous non-RDF information sources, such as relational databases, CSV, XML, etc. through RDF views constructed on top of them. Users are allowed to query the virtual RDF data using a standard query language (SPARQL) without materializing the RDF view. Instead, the system automatically translates the user-given query to non-SPARQL queries for the information sources (e.g., SQL) according to the predefined mapping specification, and the partial (intermediate) query results from the sources are then converted to RDF form and returned to the user. So far, several systems have been proposed [7], [8].
One of the key challenges in VKG-based data integration is the mapping between the original data sources’ identities (or identifiers) and the URIs (uniform resource identifiers) in RDF. More precisely, each entity/resource in RDF is identified by a URI, whereas each record and/or entity mentioned in a record is determined by different identifiers, such as a relational key, an ID, etc. For this reason, a flexible way to describe the mapping between them. In the most straightforward cases, getting a URI by just adding a URI prefix to the ID value in the record is possible. On the other hand, one may want to use the URIs in an existing KG, such as DBpedia1, which requires more sophisticated entity linking from a text to the target KG to obtain an appropriate URI for an ID value. However, none of the existing VKG systems do not offer such a mechanism.
To address this problem, we propose a flexible mapping from IDs in data sources and URIs (hereafter called ID-to-URI mapping). Our idea is to use a user-defined URI function. The mapping developer is responsible for offering the specific implementation of the ID-to-URI mapping. Then, the developer may provide any implementation w.r.t. the requirements for the VKG being designed. We demonstrate the scheme’s feasibility by integrating it into our datalog-based relation-to-1https://www.dbpedia.org/979-8-3503-2445-7/23/$31.00 ©2023 IEEE 2958 RDF mapping specification. To assess the performance, we conducted several experiments using a benchmark dataset.
The rest of this paper is organized as follows. Section II introduces the preliminary knowledge necessary to understand the subsequent discussions, followed by a literature review in Section III. Section IV describes the proposed method, and the performance study is presented in Section V. Section VI concludes this paper and mentions future works.
II. PRELIMINARIES
This section explains the background terminologies and key concepts necessary for the upcoming discussions.
A. RDF (Resource Description Framework)
RDF [4] is a data format to represent the data from various information sources in a unified manner. Originally, RDF was proposed as a unified framework for describing metadata on the Web, but it has been widely used for general purposes.
The basic unit of RDF data is an RDF triple, which consists of subject, predicate, and object, where each element is either a URI (uniform resource identifier), a literal, or a blank node. More precisely, a subject may be either a URI or a blank node; a predicate can only be a URI; and an object may be a URI, a literal, or an empty node.
A set of RDF triples form an RDF graph, which can be modeled as a labelled directed graph in which subjects and objects are nodes and predicates are labeled edges.
B. SPARQL (SPARQL Protocol and RDF Query Language)
SPARQL [5] is a standard query language for querying RDF data. The basic syntax of SPARQL comprises SELECT clause for specifying return variables, WHERE clause for identifying basic graph patterns (BGPs) that define the subgraph to be retrieved, and FILTER clause for filtering out candidate results in terms of filtering conditions. In this work, we assume that users issue queries using SPARQL to express their information needs against the target VKG.
C. View-based Data Integration based on GAV (Global-As-View)
Global-As-View (GAV) [9] is a method of view-based data integration over relational databases, where the integrated (or target) schema is defined as a view constructed on top of the query results against the data sources. One of the key features of GAV is the simple algorithm for converting the queries against the integration schema to those against the original information source. On the other hand, a drawback is that the cost of updating mapping rules is high when adding or changing information sources.
In this study, we store RDF data using a fixed relational schema where. Specifically, RDF triples are divided according to the properties. Triples with the same properties are treated in the relations where the property is the relation name, and the attributes are the subject and object. This method allows an arbitrary set of RDF triples to be represented as a relation consisting of multiple fixed attributes (subject and object), which can be integrated into GAV.
III. RELATED WORKS
A. Mapping Information Sources to RDF Triples
Using RDF as a data model to represent information sources in a unified manner is effective due to the flexibility of RDF’s data structure. However, to integrate the original information sources into the RDF schema, the RDF must be represented appropriately as a URI for individual entities. At the same time, it needs to be more obvious to derive proper URIs from the information source.
Therefore, we propose several methods for converting information source records into corresponding URIs. The first is where the URI can be derived by a simple conversion based on specific attribute values of the information source or where the URI is directly stored. The second method maps keywords in the source data to entities in knowledge bases such as Wikidata and DBpedia. Specifically, existing technologies such as Entity Linking are used to identify the corresponding URI.
B. RDF Mapping Languages
There are methods to describe the correspondence between RDF triples and non-RDF information sources and to generate RDF data from the source data based on the correspondence. The language developed to describe the correspondence between RDF triples and information sources is called a mapping language. There are R2RML (RDB to RDF Mapping Language) [10] and RML (RDF Mapping Language) [11]. R2RML is a mapping language describing correspondence relationships among information sources in relational data format. RML is a mapping language that extends R2RML to include information sources such as CSV, JSON, TSV, and XML and supports more data formats than R2RML.
It is assumed that URIs corresponding to entities required for generating RDF can be generated by adding a URI prefix to specific attribute values of information sources. Considering practicality, it is necessary to support other URI generation methods.
C. Entity Linking
In addition to URI generation by adding URI prefixes, which R2RML and RML support, other methods have been studied to infer a reference to an entity corresponding to a text or database record. Such methods for estimating the entity to which a text or record refers are collectively called Entity Linking. Specifically, given a text (or record), a matching entity from the set of entities in the target knowledge base is returned. Examples are Wikification [12] and DBpediaSpotlight [13], which compute candidate URIs of Wikipedia and candidate URIs of DBpedia from keywords, respectively.
In this study, we allow the administrator to specify any method for generating URIs in the post-integration RDF data, including adding URI prefixes and using entity linking. Therefore, it enables more practical data integration.
D. Data Integration System using SPARQL
While it is expected that data will be published in RDF data format, as represented by Linked Open Data (LOD) [14], most existing databases exist as non-RDF data, such as relational databases, CSV, and XML. Therefore, a system that integrates non-RDF information sources as virtual RDF data and enables querying with SPARQL has been proposed. [7], [8]
-
Ultrawap: In the data integration system, Ultrawap [8], the input is a SPARQL query, and the input BGP is decomposed into triple patterns. The input SPARQL query is rewritten into a query of the actual information sources by using the correspondence between the decomposed triple pattern and the original information sources. After obtaining the search results of the information sources from the rewritten query, the query is converted into the URI of the RDF data based on the predefined mapping language, and the search results requested by the user are output.
-
Ontop: The data integration system Ontop [7] uses SPARQL queries as input and outputs the search results of SPARQL queries, similar to Ultrawap. Ontop is the latest method among data integration systems with SPARQL queries and GAV mapping rules.
IV. THE PROPOESD METHOD
We propose a VKG system for relational data integration that allows users to query multiple relational databases through a unified RDF view. The mapping between RDF view and relational databases is based on GAV (global-as-view), and the system administrator describes the integrated RDF data as the result of queries to the information sources.
To allow flexible mapping between the URIs in the RDF view and IDs in the information sources, we allow the administrator to use a user-defined URI function, allowing administrators to use different methods to specify the ID-to-URI mapping. Indeed, there are multiple methods for mapping an ID to URI, and they must be set appropriately for each information source. We assume that the system administrator implements a function named URI, and its inverse function URI−1 appropriately. It enables practical integration based on the circumstances of each information source.
A. System Components
The system proposed in this study consists of four elements, as shown in Fig. 1. The four elements are information sources of the data to be integrated, a target ontology to represent the integrated data as RDF, a mapping to express the correspondence between the target ontology and the information sources of the data to be combined, and a URI function used to define the mapping.
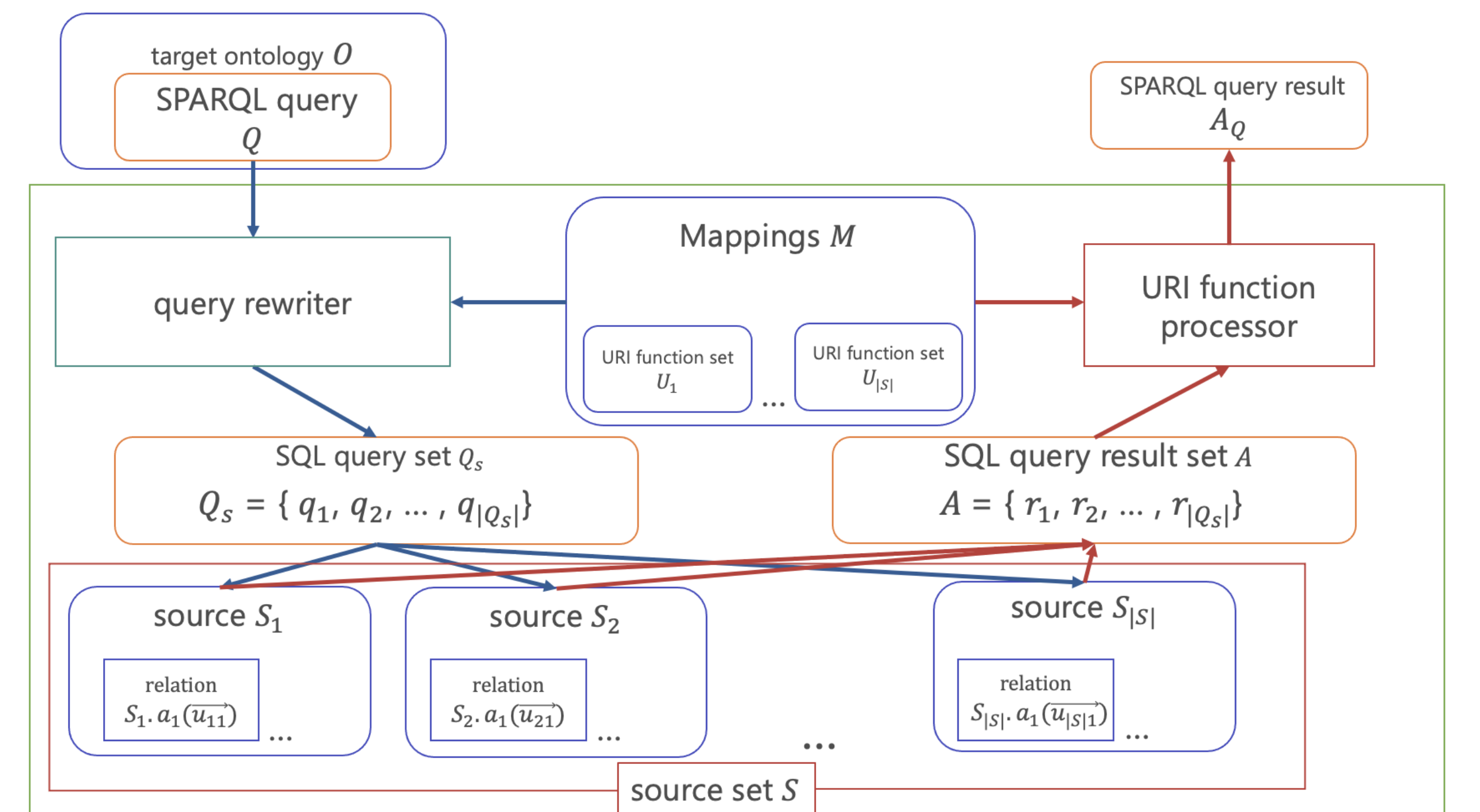
Fig. 1. System overview.
-
Infomation Sources: In this study, we assume relational databases as information sources. The set of information sources is defined as \(S= \lbrace S_1,S_2,...,S_{|S|}\rbrace \). Each information source \(S_i\) is represented as \(S_i = {S_{i.s_1}(\bold{u}_1),...,S_{i.s_{|S_i|}}(\bold{u}_{|S_i|})}\) using a relation \(s\) and its attribute set \(\bold{u}\).
-
Target Ontology: To represent the integrated data as RDF in a unified manner, we use a target ontology. In this study, we define the target ontology as \(O= \lbrace{t_1,t_2,...,t_{|O|}}\rbrace\). \(t_i = p_i(s_i,o_i)\) is an element of the target ontology and is an RDF triple representing the integrated data. In this case, \(s_i\), \(p_i\), \(o_i\) are the RDF triple’s subject, predicate, and object.
-
URI Function: When defining a mapping between an information source and a target ontology, generating a URI corresponding to the entity is necessary. In this study, the system administrator defines this as a custom-made function URI function. A URI function returns the corresponding URI for an input record. The simplest example would be to return the URI contained in a specific attribute of the information source or to add a particular URI prefix to the ID attribute. It is also possible to obtain the entity and its URI corresponding to a record or text by calling entity linking such as Wikification [12] or DBpediaSpotlightCite [13] in the function URI.
-
Relation-to-RDF Mapping: The mapping between the target ontology and the information sources to be integrated is specified by GAV, where the target ontology is defined as a view of the information sources. However, the target ontology (RDF data) is not a relation. For this reason, we regard the RDF triples as a set of relations with fixed attributes, i.e., RDF triples \((s,p,o)\) are regarded as relations \(p(s,o)\). Thus, we can describe the relation-to-RDF mapping as a relation-to-relation mapping. In this study, we define the set of mappings as \(M = \lbrace {m_1,m_2,...,m_{|M|}\rbrace}\). For each mapping \(m_i\), we denote the following equation (1).
\begin{align} m_i : p(URI(s),f(o)) ⊇ q \qquad (f ∈\lbrace{URI,R}\rbrace) \end{align}
Where q is a datalog query described by the information source to be integrated, \(p(URI(s), f(o))\) is an RDF triple that is an element of the target ontology. The subject is a URI, and the object is a URI or literal. In other words, the function f is a URI function if the target is a URI or a function R that returns a string if the target is a literal.
\begin{align} mi : ∀s,o(∃y_1,…,y_n(S_{k\cdot s_a}(\bold u_a)),…,S_{l\cdot s_b}(\bold u_b)) \nonumber \\ ⇒p(URI(s),f(o))) \qquad (f ∈\lbrace{URI,R}\rbrace) \end{align} In this case, \(s\), \(o\) are variables used in the query results and attribute variables used in the attribute set \(\bold u\). Also, \(y_1,...,y_n\) are attribute variables used in the attribute set \(\bold u\), which, unlike \(s\), \(o\), are not used in the query results.
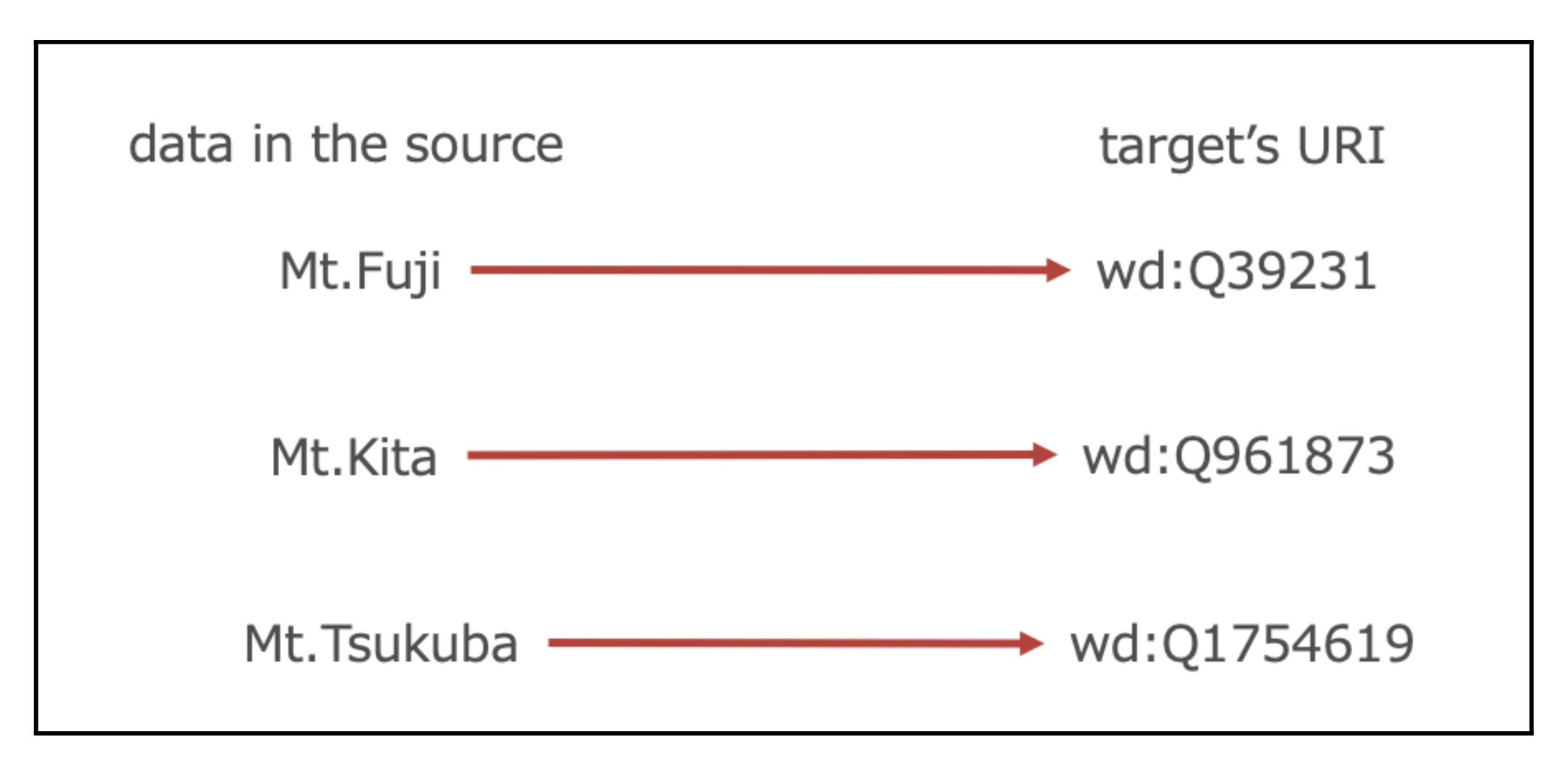
Fig. 2. Example of one-to-one URI mapping.
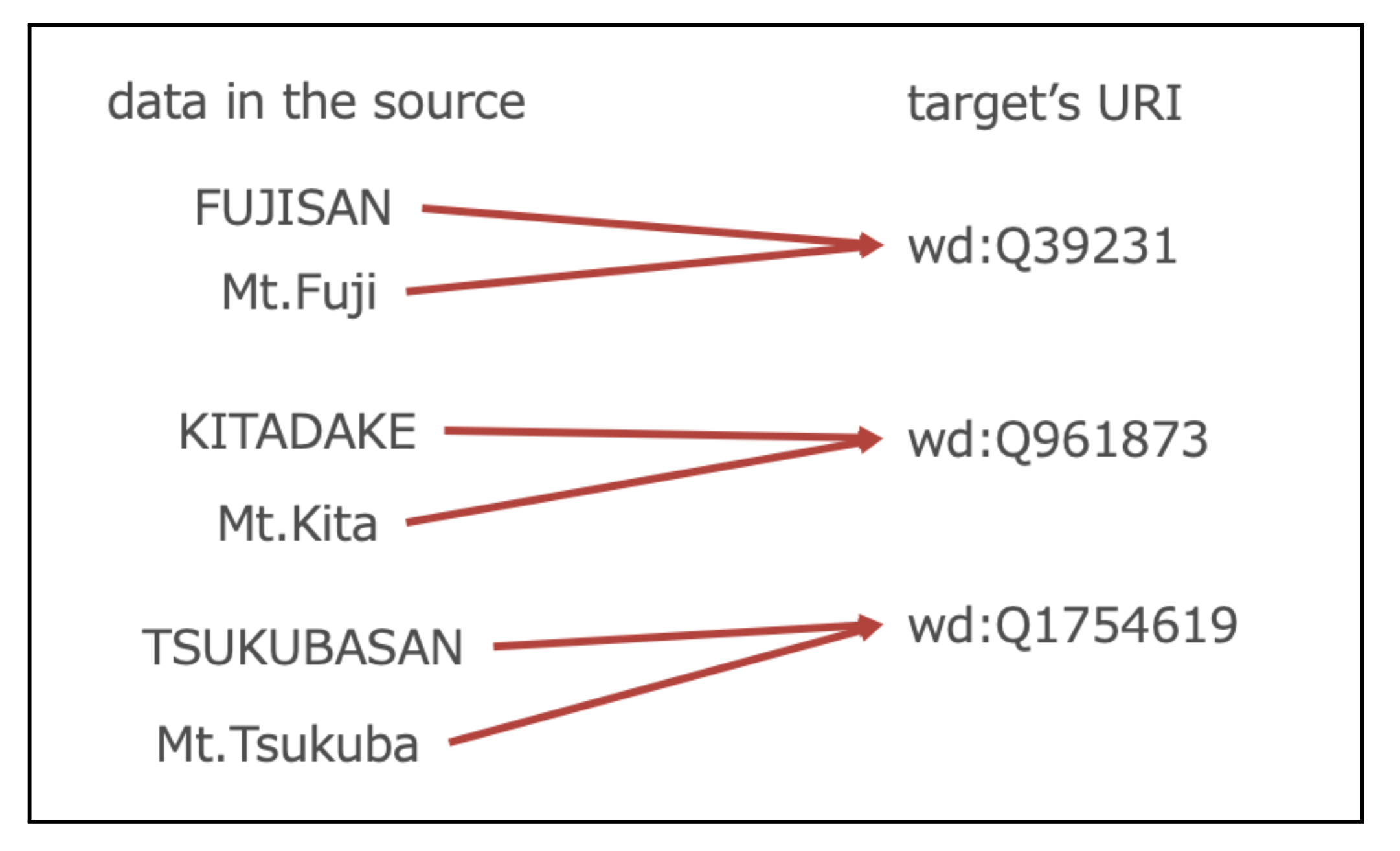
Fig. 3. Example of many-to-one URI Mapping
B. Classification of URI Functions
URI functions can be classified according to the correspondence between the definition domain of the function (the data of the information sources) and its value domain (the target URI).
-
One-to-one mapping: A URI function is called a one-to-one function when the source data and the target’s URI correspond one-to-one. Fig. 2 shows an example of a URI function that maps a source of information on Japanese mountains to a URI in Wikidata. In Fig. 2, the URI function returns wd:Q39231 given the data in the source, Mt. Fuji.
-
Many-to-one Mapping: A URI function is called a many-to-one function when the source data and the target’s URI correspond many-to-one. Fig. 3 shows an example of a URI function that maps a source of information on Japanese mountains to a URI in Wikidata. In Fig. 3, the URI function returns wd:Q39231 given the data in the source, Mt. Fuji.
The many-to-one URI function differs from one-to-one in that it returns the same wd:Q39231 when it receives Mt.Fuji or ”FUJISAN”.
C. Query Processing
In the data integration system proposed in this study, the SPARQL language is used when users query the integrated data. A query written in SPARQL consists of BGP and FILTER. BGP is a set of triple patterns and is the body of the query. FILTER is the part that describes the conditions of variables used in the triple patterns of BGP.
Algorithm 1 Query Processing
Require: SPARQL query Q,
data integration system I= ⟨S,O,M⟩
Ensure: SPARQL query answer AQ
1: Initialize Qsql
2: for (ps(ss,os)) ∈Q do
3: Initialize Qor
4: for ((pm(URI(sm),f(om)) ⊇ q(sm,om)) (f ∈ {URI,S})) ∈M do
5: if ps == pm then
6: Qor ←addORQuery(Qor ,q(sm,om))
7: end if
8: end for
9: Qsql ←addANDQuery(Qsql,Qor )
10: end for
11: A←Query(Qsql,S)
12: AQ ←Mapping(A,M)
13: return AQ
The proposed data integration system receives a SPARQL query as input and outputs tabular data, where each record is the result of a set of variables in the SELECT clause specified in the SPARQL query.
In addition, the proposed data integration system handles virtual RDF data, so SPARQL queries cannot be directly applied to them. Therefore, we create an SQL query equivalent to a SPARQL query using the mapping M and apply the URI function to the query result of the SQL query. Thus, users can obtain the same search results as when they execute a SPARQL query.
-
Query Processing Flow: We consider creating an SQL query equivalent to a SPARQL query using the mapping M. In this case, the Query Unfolding algorithm is used to create the SQL query. Algorithm 1 shows the algorithm of query processing.
In the query processing, given a SPARQL query \(Q\) for the data integration system \(I= ⟨S,O,M⟩\), we return the answer of the SPARQL query \(Q\). First, initialize \(Q_{sql}\) (Line 1), which is the query against the sources. Then, for each triple pattern, the triple pattern can be replaced with the SQL query that the triple pattern encompasses by using a mapping \(m\) that matches the triple pattern (Lines 2-10). Each mapping \(m\) represents the correspondence between RDF triples and information sources, which is also the correspondence between the triple pattern and the query of the information sources.
Here, since a triple pattern may encompass multiple SQL queries, in this case, the logical OR of the multiple SQL queries can be used to answer the query for the information source maximally. In the algorithm, corresponding to Lines 4-8, the function \(addORQuery(Q_{or} ,q(s,o))\) is used to express the above pattern. To illustrate this function with a concrete example, the return value of \(addORQuery((q_1 ∩ q_2), q_3)\) is \(((q_1 ∩ q_2) ∪ q_3)\).

Fig. 4. Example 1: SPARQL query without FILTERSince the relation between each triple pattern in the BGP of a SPARQL query is a logical product, replacing a triple pattern with an SQL query combines the SQL queries between different triple patterns with a logical product. In the algorithm, corresponding to Line 9, the function \(addANDQuery(Q_{sql},q(s,o))\) is used to represent the above pattern. To illustrate this function with a concrete example, the return value of \(addANDQuery((q_1 ∩ q_2), q_3)\) is \(((q_1 ∩ q_2) ∩ q_3)\).
With the previous operations, the SPARQL query can be converted to an SQL query to perform queries against the actual information sources. By executing the obtained SQL query against the actual information source, we can obtain the answer \(A\) of the SQL query. The obtained SQL query answer \(A\) is not the SPARQL answer \(A_Q\) since no URI functions are applied to it.
Finally, by mapping the SQL query answer \(A\) to the appropriate answer for the SPARQL query using the mapping \(M\), we can obtain the answer \(A_Q\) for the SPARQL query.
-
Query processing without FILTER that includes URIs: For example, we will explain how the SPARQL query of the Fig. 4 can be replaced by an SQL query when the mapping is below.
-
mappings \begin{align} &– p1(URI(s),R(o)) ⊇q_1(s,o) \nonumber \\ &– p1(URI(s),R(o)) ⊇q_2(s,o) \nonumber \\ &– p2(URI(s),URI(o)) ⊇q_3(s,o) \nonumber \\ &– p3(URI(s),R(o)) ⊇q_4(s,o) \nonumber \\ \end{align}
The given SPARQL query can be notated according to the left-hand side of the mapping as follows. However, the symbol for variables in the SPARQL query, ”?” is omitted.
\begin{align} ∀x_1,x_2(∃y_1,y_2(p_1(y_1,x_1),p_2(y_1,y_2),p_3(y_2,x_2))) \nonumber \end{align}
Based on the given mappings, the above SPARQL query can be replaced with an SQL query and expressed as follows.
\begin{align} ∀x_1,x_2(∃y_1,y_2((q_1(y_1,x_1) ∪ q_2(y_1,x_1)) ∩ \nonumber \\ q_3(y_1,y_2) ∩ q_4(y_2,x_2))) \nonumber \end{align}
If we execute the above SQL query against the information sources and then perform mapping on the query results, we will get the answer to the SPARQL query.

Fig. 5. Example 2: SPARQL query with FILTER that includes URIs
-
Query processing with FILTER that includes URIs: In the query processing described in the previous section, if the search condition of FILTER does not include a URI, we can obtain the answer of the SPARQL query without any problem.
However, if the search condition of FILTER includes URIs, the search condition, including URIs, cannot be carried over to the SQL query when replacing the triple pattern in the SPARQL query with the SQL query. This is because all the data of the actual sources are represented as strings before applying the URI function. Therefore, in the proposed data integration system, the data manager can determine the URI function according to the size of the information sources. In this study, we denote the conversion function from the search condition corresponding to a SPARQL query that includes a URI to the search condition corresponding to an SQL query as \(URI^{−1}(∗)\). Note that the input of the function mentioned above is only URIs.
For example, we will explain how a SPARQL query containing a FILTER of the Fig. 5 is replaced by an SQL query when the mapping is as follows.
- mappings \begin{align} &– p_1(URI(s),R(o)) ⊇ q_1(s,o) \nonumber \\ &– p_1(URI(s),R(o)) ⊇ q_2(s,o) \nonumber \\ &– p_2(URI(s),URI(o)) ⊇ q_3(s,o) \nonumber \\ &– p_3(URI(s),R(o)) ⊇ q_4(s,o) \nonumber \\ &– p_4(URI(s),URI(o)) ⊇ q_5(s,o) \nonumber \\ \end{align}
For FILTER in a SPARQL query, ex:c is a URI. The given SPARQL query can be expressed on the left-hand side of the mapping as follows. However, the symbol for variables in the SPARQL query, ”?” is omitted.
\begin{align} &∀x_1,x_2(∃y_1,y_2,y_3(p_1(y_1,x_1), \nonumber \\ &p_2(y_1,y_2),p_3(y_2,x_2),p_4(y_2,y_3),(y_3 = ex:c))) \nonumber \\ \end{align}
Based on the given mappings, the above SPARQL query can be replaced with an SQL query and expressed as follows.
\begin{align} &∀x_1,x_2(∃y_1,y_2,y_3((q_1(y_1,x_1) ∪ q_2(y_1,x_1)) ∩ \nonumber \\ &q_3(y_1,y_2) ∩ q_4(y_2,x_2) ∩ (q_5(y_2,y_3),y_3θURI^{−1}(ex:c)))) \nonumber \\ \end{align}
The search condition described by FILTER in the SPARQL query is expressed as \(y_3θURI^{−1}(ex:c)\) in the SQL query. Note that \(θ\) is an operator. \(θ\) is used instead of = because the URI function determines the URI according to the range of possible data values. Therefore, another operator may be used instead of = when the SQL query asks for the information sources.
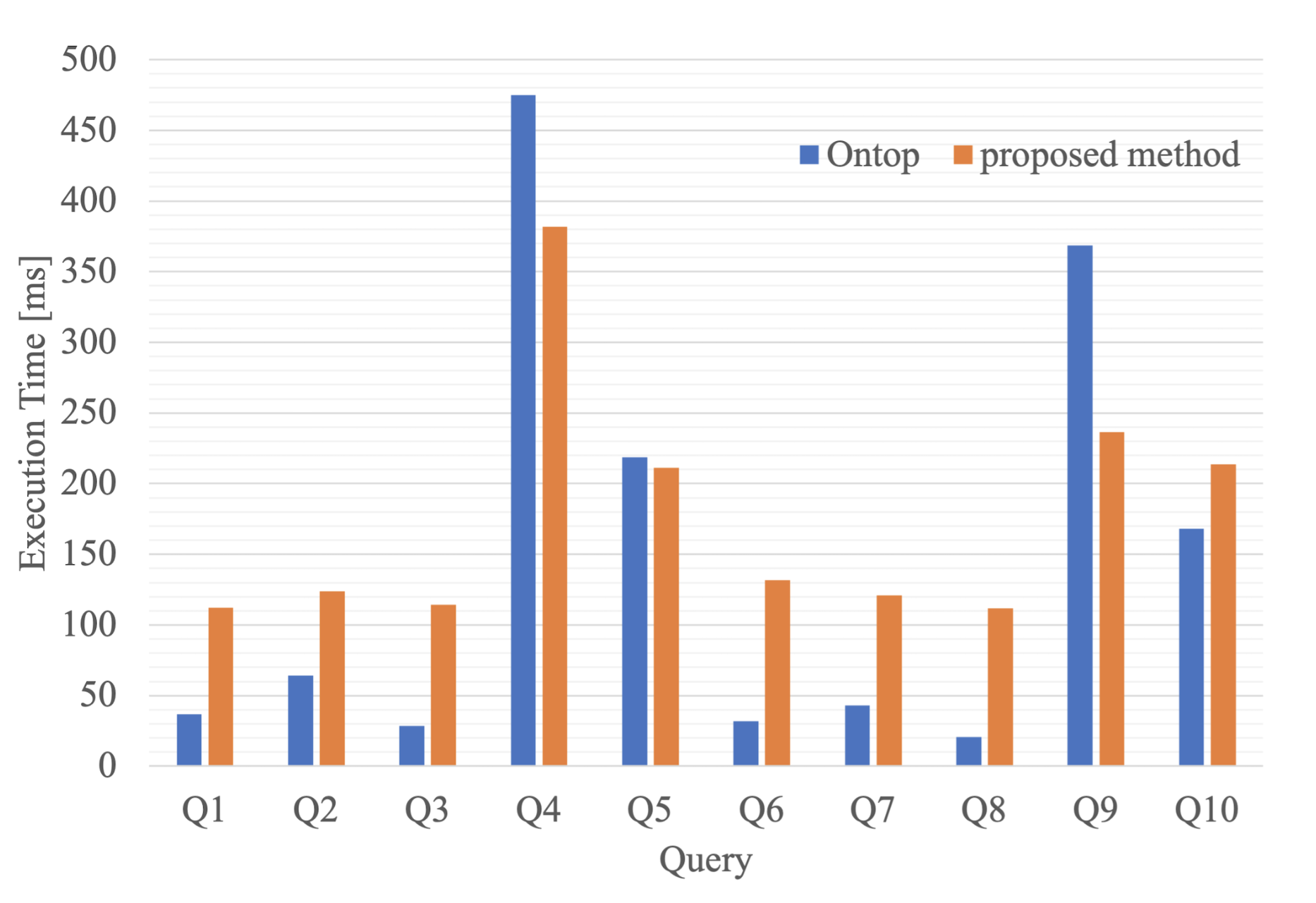
Fig. 6. Result of Experiment 1
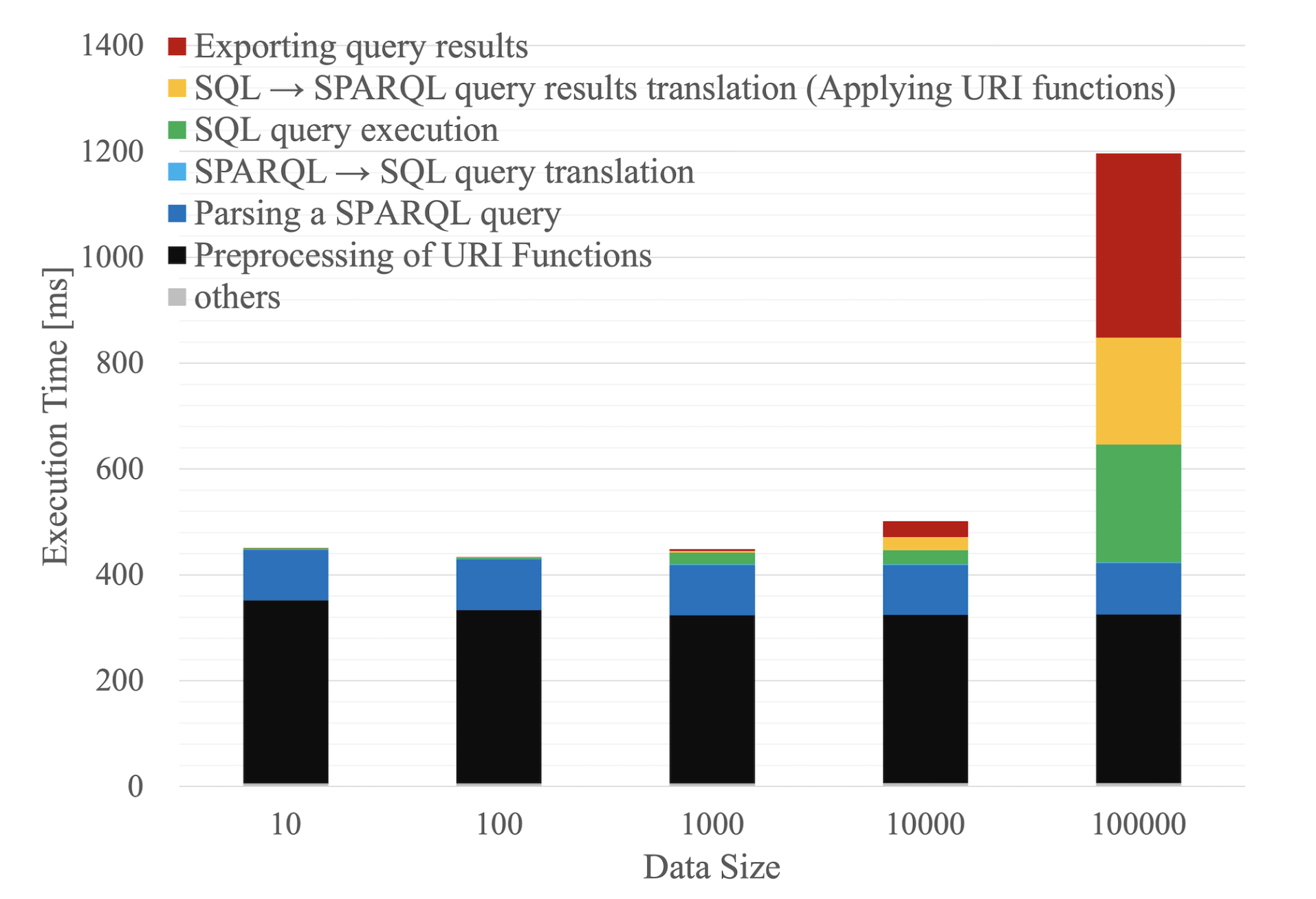
Fig. 7. Result of Experiment 2
V. EXPERIMENTS
In these experiments, we evaluated the validity of the proposed method regarding query processing.
A. Environment
We implemented the data integration system using Python 3.9.17 and PostgreSQL 13.11. The runtime environment was macOS 13.5.2 with an Intel® Core™ i5-1038NG7 CPU.
B. Experiment 1
In the first experiment (Experiment 1), we compared the query processing time of the virtual data integration system implemented according to the proposed method with Ontop, a virtual data integration system, as a comparison method.
-
Procedure: We queried each proposed method and Ontop and measured the time until the query results were returned. The same datasets, queries, and databases were used for the proposed method and Ontop. We used Ontop CLI 5.0.2.
-
Dataset: The dataset used was the NPD benchmark [15]. It is a dataset released by the development team of Ontop and is a set of statistical data from the Norwegian Petroleum Administration, processed for benchmarking purposes.
-
Evaluation query: The evaluation queries were those prepared in the NPD benchmark and did not require ontology inference, and in ForBackBench [16] that could be used in the NPD benchmark and do not require ontology inference, totalling 10 queries.
-
Results: Figure 6 shows the experimental results showing that Ontop was faster with queries of relatively short processing times, such as Q1 to Q3, Q6 to Q8, and Q10. On the other hand, for the queries with longer query processing times, such as Q4, Q5, and Q9, the proposed method outperformed Ontop.
-
Discussion: The reason for the experimental results, as shown in Fig. 6, could be attributed to the processing time of the query parsing used in the proposed method. In the proposed method, the textual SPARQL query given by the user was structured into a JSON file and then converted into an SQL query using a mapping file. The processing time of structuring a textual SPARQL query into a JSON file was constant because our method uses sparqljs [17]. Therefore, the processing time of sparqljs affected the experimental results for queries like Q1 ˜Q3, Q6 ˜Q8, and Q10, which required only a short processing time.
C. Experiment 2
In the second experiment (Experiment 2), we examined how much overhead the URI function in the proposed method had depending on the scale of the dataset.
-
Procedure: The query in this experiment was the output of all tuples in the dataset. The number of times the URI function was applied was the same as the scale size of the dataset. If the number of tuples in the dataset was 1,000, the number of times the URI function was applied was 1,000.
The URI function used in this experiment was based on the correspondence table of strings and URIs in the dataset, which was read when the query was processed.
-
Dataset: The dataset was extracted from Wikidata [18] for books. The dataset consists of a total of 100,000 tuples (rows). In our experiments, we randomly extracted tuples from the dataset to create a dataset with multiple scales. The dataset had five scales: 10, 100, 1,000, 10,000, and 100,000.
-
Results: Fig. 7 shows the experimental results of the above dataset and queries. The bar graphs consist of each processing time. URI function was used when the system translated a SPARQL query into SQL query (light blue bar in Fig. 7), and translated SQL query results into SPARQL query results (yellow bar in Fig. 7).
From the results, the larger the data size, the longer the processing time from SQL query results to SPARQL query results, which applied the URI function. In addition, the larger the data size, the longer the processing time required to execute the SQL query and to export the SPARQL query results.
-
Discussion: From the experimental result, the URI function, which was the crucial element of the proposed method, was affected by the processing time as the data size increased. However, the increase in the processing time is linear.
Therefore, the URI function with a correspondence table is considered practical.
In addition, the time required for exporting the query result and processing the SQL query result also increased linearly.
VI. CONCLUSION
In this study, we proposed a data integration system that could specify a mapping technique for each correspondence between RDF triples and information sources by introducing a custom-made URI function. We can query heterogeneous information sources with SPARQL queries. Experimental results show that the proposed method can obtain the same query results as Ontop, an existing method, by appropriately setting the mapping and URI functions. Furthermore, the query processing time was comparable to that of the existing method.
In future work, a data integration system using a custom-made URI function and LAV (Local As View) [9] as a mapping rule is considered. Although the mapping rule of the proposed method is based on GAV, which makes the proposed method’s implementation easy, the proposed method’s data integration system requires updating the mapping and the URI function each time the relations of the information sources are frequently added or deleted. By using another mapping rule, LAV, the mapping is expected to be updated less frequently than GAV, even if the relationships of information sources are frequently added or deleted.
ACKNOWLEDGEMENTS
This paper is based on results obtained from “Research and Development Project of the Enhanced Infrastructures for Post-5G Information and Communication Systems” (JPNP20017) commissioned by NEDO, JST CREST Grant Number JPMJCR22M2, and JSPS KAKENHI Grant Numbers JP22H03694 and JP23H03399.
REFERENCES
- [1] “Open Data 100,” https://www.digital.go.jp/resources/data case study.
- [2] “DATA.GO.JP,” https://data.e-gov.go.jp/info/en.
- [3] Serge Abiteboul and others, “Web Data Management,” http://webdam.inria.fr/Jorge/files/wdm.pdf.
- [4] Graham Klyne and others, “Resource Description Framework (rdf): Concepts and abstract syntax,” https://www.w3.org/TR/rdf10-concepts/.
- [5] Steve Harris and Andy Seaborne and EricPrud’hommeaux, “Sparql 1.1 query language,” W3C recommendation, no. 10, p. 778, 2013.
- [6] G. Xiao, L. Ding, B. Cogrel, and D. Calvanese, “Virtual Knowledge Graphs: An Overview of Systems and Use Cases,” Data Intelligence, vol. 1, no. 3, pp. 201–223, 06 2019. [Online]. Available: https://doi.org/10.1162/dint\ a\ 00011
- [7] O. Corcho, D. Calvanese, B. Cogrel, S. Komla-Ebri, R. Kontchakov, D. Lanti, M. Rezk, M. Rodriguez-Muro, and G. Xiao, “Ontop: Answering sparql queries over relational databases,” Semant. Web, vol. 8, no. 3, p. 471–487, jan 2017. [Online]. Available: https://doi.org/10.3233/SW-160217
- [8] J. F. Sequeda, M. Arenas, and D. P. Miranker, “Obda: Query rewriting or materialization? in practice, both!” in The Semantic Web – ISWC 2014, P. Mika, T. Tudorache, A. Bernstein, C. Welty, C. Knoblock, D. Vrandeˇ ci´ c, P. Groth, N. Noy, K. Janowicz, and C. Goble, Eds. Cham: Springer International Publishing, 2014, pp. 535–551.
- [9] Y. Katsis and Y. Papakonstantinou, View-Based Data Integration. New York, NY: Springer New York, 2018, pp. 4452–4461. [Online]. Available: https://doi.org/10.1007/978-1-4614-8265-9 1072
- [10] Souripriya Das, Seema Sundara, Richard Cyganiak, https://www.w3.org/TR/r2rml/.
- [11] A. Dimou, M. V. Sande, P. Colpaert, R. Verborgh, E. Mannens, and R. V. de Walle, “Rml: A generic language for integrated rdf mappings of heterogeneous data,” in LDOW, 2014. [Online]. Available: https://api.semanticscholar.org/CorpusID:6564357
- [12] R. Mihalcea and A. Csomai, “Wikify! linking documents to encyclopedic knowledge,” in Proceedings of the Sixteenth ACM Conference on Conference on Information and Knowledge Management, ser. CIKM ’07. New York, NY, USA: Association for Computing Machinery, 2007, pp. 233–242. [Online]. Available: https://doi.org/10.1145/1321440.1321475
- [13] “DBpediaSpotlight,” https://www.dbpedia-spotlight.org/.
- [14] Tim Berners-Lee, https://www.w3.org/DesignIssues/LinkedData.html.
- [15] D. Lanti, M. Rezk, M. Slusnys, G. Xiao, and D. Calvanese, “The npd benchmark for obda systems,” in SSWS@ISWC, 2014. [Online]. Available: https://api.semanticscholar.org/CorpusID:6565909
- [16] A. Alhazmi, T. Blount, and G. Konstantinidis, “Forbackbench: A benchmark for chasing vs. query-rewriting,” Proc. VLDB Endow., vol. 15, no. 8, p. 1519–1532, apr 2022. [Online]. Available: https://doi.org/10.14778/3529337.3529338
- [17] Ruben Verborgh, “SPARQL.js – A SPARQL 1.1 parser for JavaScript,” https://github.com/RubenVerborgh/SPARQL.js/.
- [18] “Wikidata,” https://www.wikidata.org/wiki/Wikidata:Main Page.